*Another post moved over from my old blog. Since I wrote this, a coworker modified the code to extract data from multiple Excel workbooks and tabs in a similar fashion. At some point I’ll try to add that addendum.
Problem:
We’ve all heard it before – “Well I get the crucial financial numbers from this Access Database…”. Or even worse, “we have hundreds of access databases all over the place with varying schemas”. On a recent project I was faced with the later – several hundred Access DBs (mdb files) that had accumulated over a number of years, in various places across the network, all with different schemas. In the client’s defense, some of this was an outside 3rd party’s doing and they had since implemented an enterprise class solution for the process going forward. Never the less, I was tasked with extracting all of this legacy Access data into SQL Server.


 🙁
🙁
I figured I would just be able to use a For Each Loop within SSIS to extract each mdb file and just drop it to SQL Server. I quickly realized however that because every Access DB could potentially have a different schema, I would need to dynamically handle the schemas in each source file. I briefly thought about using BIML (see my recent posts about Business Intelligence Markup Language) to dynamically create the SSIS packages, but I really didn’t want hundreds of packages or components since this was a one and done job. So for better or for worse I turned to the trusty Script Task.
Solution:
So what I needed to do was:
- Connect to each Access DB file in different locations across the network
- Create the table schema for that specific mdb file in SQL Server
- Copy the data from the Access file to SQL Server
- Run some other processing stored procedures not related to this post
Turns out there was also a 1b) – map each file location as a network drive using a separate Active Directory account. There was no need to keep the data after the last processing step was complete, so I was able to drop the created SQL Server tables when I was done.
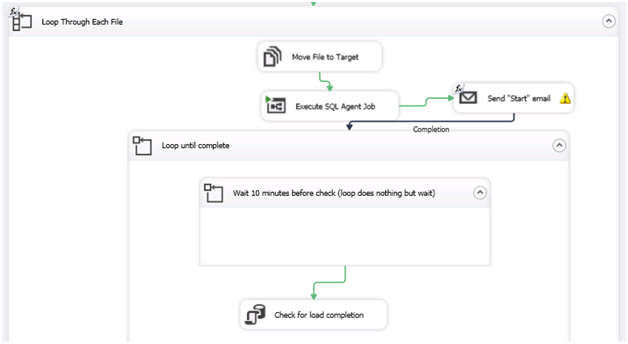
Here is an overview of the control flow of my completed SSIS package:
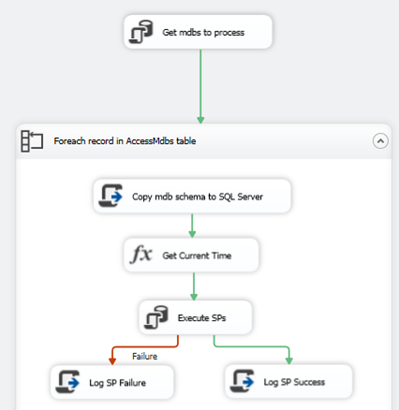
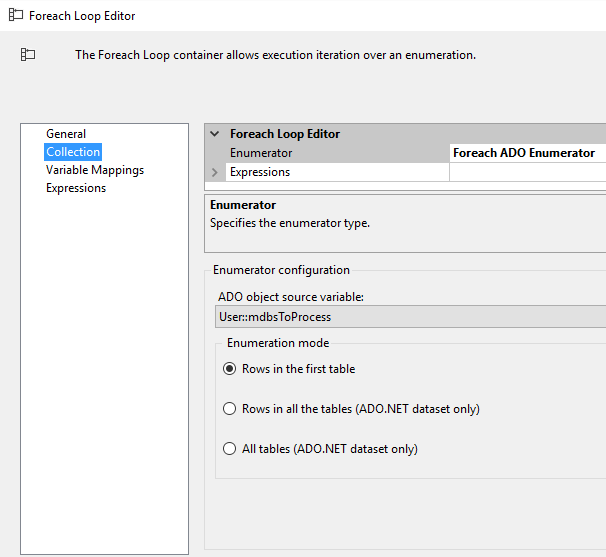
First I use an Execute SQL Task to select all of the file names and locations of the mdb files from a pre-populated table (thankfully I had a spreadsheet of all the file names and locations). To set up the For Each Loop to loop through all the rows returned in the Execute SQL Task, we need to first create a User Variable of type Object – here I called it “mdbsToProcess”. Then in the Execute SQL Task properties, we set the ResultSet property to Full Result Set.

Then we click on the Result Set option and set the result set to the object variable we created.

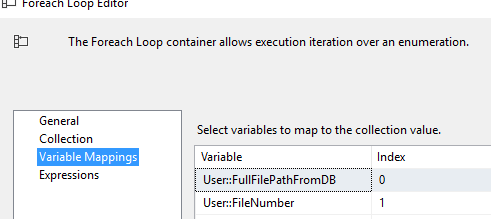
Next I use a For Each Loop to loop through each of the mdb files I need to process. The For Each Loop is set up as follows to use the mdbsToProcess variable, and loop through each record to get information we need for each mdb file.
For the final code sample – click here. I’ll walk through it below. This is just a copy/paste from the SSIS Script Task, so please ignore all the SSIS default stuff.
After the Script Component generates and loads all of the tables from the mdb file into SQL Server, I simply get the current time, execute some other stored procedures to process the data unrelated to this post, then log the results.
Code Explanation:
By no means am I am App Dev guy, so feel free to improve upon this and let me know. But below is an overview of the more interesting parts of the Script Task code. First we set up all our variables (its quick and dirty so some are hard coded, others are passed in from SSIS).
public void Main()
{
string FullFilePath = Dts.Variables["User::FullFilePathFromDB"].Value.ToString(); //Full network file path and name of mdb file
string TargetServer = Dts.Variables["$Package::TargetServer"].Value.ToString(); //Target SQL Server
string TargetDB = Dts.Variables["$Package::TargetDB"].Value.ToString(); //Target SQL DB
string tableName = null; //name of table in source
string TargetTableName = null; //name of table being created/populated
string DropTableSQL = null;
string NetworkDrivePassword = "MyNetworkDrivePassword";
string NetworkDriveUser = "MyNetworkDriveUserName";
string NetworkSharePath = "\\MyNetworkPath\Share$";
intCountCreatedTables = 0; //Used in log file
string SourceConnString = ("Provider=Microsoft.Jet.OLEDB.4.0;" + "Data Source=" + FullFilePath);
string TargetConnString = ("Data Source=" + TargetServer + "; Password=MyPassword;User ID=MyUserName;Initial Catalog=" + TargetDB + ";");
string command;
command = "/C NET USE " + NetworkSharePath + "/delete"; //If share mapped, disconnect to prevent multi "user" error
//WriteToLog("Executing Cmd Line: " + command);
ExecuteCommand(command, 5000);
command = "/C NET USE " + NetworkSharePath + " /user:" + NetworkDriveUser + " " + NetworkDrivePassword; //grant access
//WriteToLog("Executing Cmd Line: " + command);
ExecuteCommand(command, 5000);
Then we execute 2 NET USE commands to first delete any existing mapped network drive by the given name, and then to map it based on the given credentials. This is only necessary if the credentials you run the SSIS package under do not have access to the network shares. I found I had to first delete it if it existed or I could run into a “multi user” error. These commands are executed by the ExecuteCommand() method which just runs the NET USE commands via cmd.exe.
Next we use the GetSchema method on the Source Connection (AKA our Access file/OleDbConnection) to populate a data table with every table within the mdb file. Note that we specify the “Tables” schema object type.
OleDbConnection SourceConn = new OleDbConnection(SourceConnString);
SqlConnection TargetConn = new SqlConnection(TargetConnString);
SourceConn.Open();
WriteToLog("Connect to File # " + Dts.Variables["User::FileNumber"].Value + " in " + FullFilePath);
DataTable DBTabsTables = SourceConn.GetSchema("Tables");
SourceConn.Close();
Now that we have a table of all of the Access file tables, we iterate through each one in the DBTabsTables DataTable and generate our DROP and CREATE scripts which we pass to the CreateTable() method. In this case I specified the tables I wanted, but you can remove the IF statement if you want them all.
foreach (DataRow row in DBTabsTables.Rows) //For each table in mdb file
{
tableName = row["table_name"].ToString();
if(tableName == "AccessTable1" || tableName == "AccessTable2" || tableName == "AccessTable3") //only get specified tables from Access file. Or remove IF to get all tables
{
DropTableSQL = "IF OBJECT_ID('dbo."+ tableName + "') IS NOT NULL BEGIN DROP TABLE " + tableName + " END; "; //build drop table if exists SQL
CreateTable(SourceConn, tableName, TargetConn, DropTableSQL, tableName); //For the initial create, we want to use the source tableName
++CountCreatedTables;
BulkLoadTable(SourceConn, tableName, TargetConn, tableName); //For the initial bulk load, we want to use the source tableName
}
}
Within CreateTable() we again see that we use GetSchema on the connection object, but this time we use the “Columns” object type and another variable called “restrictions”. If you look a few lines from the top of the code snippet below, you can see that “restrictions” is a 4 value array of strings. You can read about the options here, but I am passing the name of the current table within the loop into the 3rdposition in the array (remember, its 0 based), which is then used in the GetSchema call to restrict it to only 1 table. So now we have a DataTable called ColumnDataTable which contains 1 record for each column in the designated table.
public void CreateTable(OleDbConnection SourceConn, string tableName, SqlConnection TargetConn, string DropTablesSQL, string TargetTableName)
{
string[] restrictions = new string[4];
restrictions[2] = tableName; //restrict which table information is returned by GetSchema
string accessTableFieldName;
DataRow myRow;
SourceConn.Open();
DataTable ColumnsDataTable = SourceConn.GetSchema("Columns", restrictions); //Fill DataTable with columns information
SourceConn.Close();
When using the schema information to build the CREATE scripts for the new SQL tables, you need to be careful about data types between OleDB and SQL Server. There is probably a better way to do this, but I used the below switch statement to brute force change the datatype names to their SQL counterparts.
//For every row in the table
for (int i = 0; i < SortedColumnsDataTable.Rows.Count; i++)
{ //Get column name and type
myRow = SortedColumnsDataTable.Rows[i];
accessTableFieldName = "[" + myRow["column_name"] + "] ";
switch (((OleDbType)myRow["data_type"]).ToString())//Change OleDBType to SQL datatypes
{
case"Boolean": accessTableFieldName += "bit";
break;
case"Currency": accessTableFieldName += "money";
break;
case"Date":
case"DBDate":
case"DBTimeStamp": accessTableFieldName += "datetime";
break;
case"VarWChar":
case"WChar":
case"VarChar":
case"Char": accessTableFieldName += "nvarchar(" + myRow["character_maximum_length"] + ")";
break;
case"UnsignedTinyInt": accessTableFieldName += "int";
break;
case"Double": accessTableFieldName += "Float";
break;
default: accessTableFieldName += ((OleDbType)myRow["data_type"]).ToString();
break;
}
Lastly, in BulkLoadTable() we execute a BCP command to copy the data from the mdb file to the newly created SQL Server table. Be sure to set the batchsize and timeout length to something that can handle the amount of data you are transferring.
public void BulkLoadTable(OleDbConnection SourceConn, string tableName, SqlConnection TargetConn, string TargetTableName) //use bcp to load data from source to target
{
OleDbCommand SelectFromCmd = newOleDbCommand("SELECT * FROM " + tableName, SourceConn);
OleDbDataReader rdr;
SourceConn.Open();
TargetConn.Open();
rdr = SelectFromCmd.ExecuteReader();
SqlBulkCopy sbc = new SqlBulkCopy(TargetConn);
sbc.DestinationTableName = TargetTableName;
sbc.BatchSize = 50000;
sbc.BulkCopyTimeout = 120;
sbc.WriteToServer(rdr);
sbc.Close();
rdr.Close();
SourceConn.Close();
TargetConn.Close();
WriteToLog("Load " + TargetTableName);
}
Summary
In this post we discussed how to use SSIS and a Script Task to iterate through any number of Access mdb files in order to import the data into SQL Server. The code used can handle Access dbs in varying schemas. This type of process can be very useful when you are dealing with a large number of legacy Access dbs and the Import Wizard isn’t practical. Hopefully this post will help someone else to upgrade/migrate a legacy business process into a more enterprise ready solution – not to allow an “Access for the Enterprise” application to continue to exist!
Erik